
MySQL 5.7.17版本中引入了MySQL Group Replication,这个是官方基于Paxos开发的,解决了数据强一致性的问题,支持强一致性的复制。是Oracle官方开发的,是自身的组件,不依赖于第三方,这样就比PXC(Percona XtraDB Cluster)在性能、稳定性、一致性方面都有很多改善。现在推荐的高可用方案是MySQL Group Replication,未来也会是MySQL Group Replication的天下。
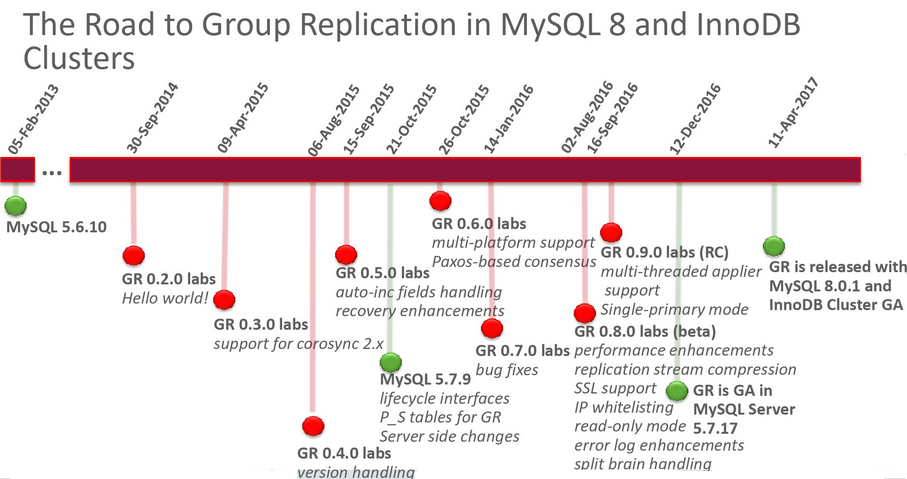
MySQL Group Replication
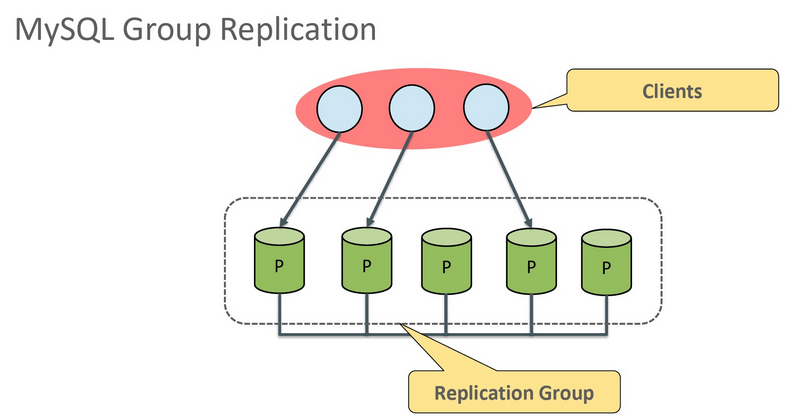
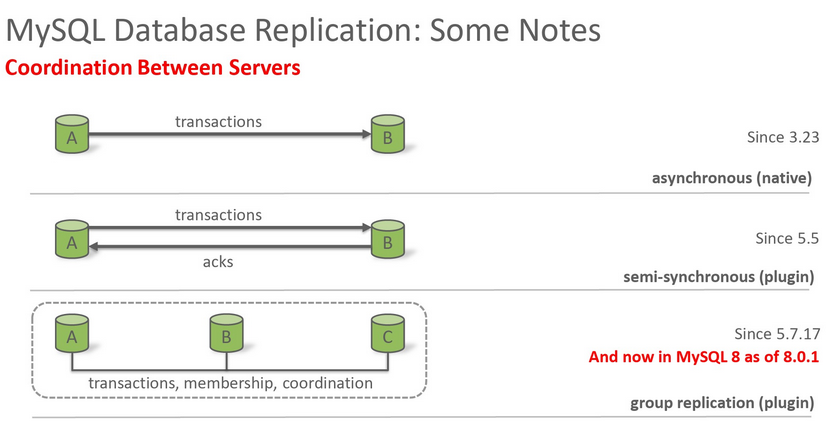
这个是在MySQL 5.7.17中发布了一个重要的功能Group Replication组复制。通过 Group Replication可以让多个MySQL节点中的数据完全一致,多主是通过参数group-replication-single-primary-mode来控制的。对其中任意一个节点执行修改后,其他节点都会自动同步,并保证数据的一致性。他有下面几个特点:
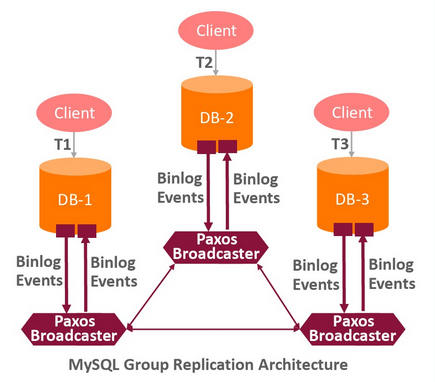
组复制与主从复制或半同步复制等有什么区别?强一致性:是通过著名的分布式一致性算法Paxos来保证各节点状态相同
高可用:只要不是大多数节点坏掉就可以继续工作
自检机制:当不同节点产生资源争用冲突时,不会出现错误,按照先到者优先原则进行处理。内置了自动化脑裂防护机制
弹性:节点的新增和移除都是自动的。新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致。如果某节点被移除了,其他节点自动感知,自动维护新的group信息
灵活:可用使用单主模式和多主模式。单主模式下,会自动选主,所有更新操作都在主上进行。多主模式下,所有节点都可以同时处理更新操作
在组复制中,大家都是MASTER,一个MASTER收到写请求后,在提交这个事务之前,必须通知其他MASTER,大家同意以后,都执行一下这个写操作,否则都不执行,这样就保证了大家的数据都一样。
在主从复制或半同步复制中,SLAVE只是MASTER的一个备份,主库的数据落地之后,并不关心备库的日志是否落库,SLAVE自己努力的尽量保持和MASTER保持一致。
下面让我们看看回复一下MySQL复制的历史,和过去的复制方式。
MySQL在复制时,我们可以指定需要复制的数据库甚至具体那些表,也可以选择要忽略的数据库,支持异步复制、半同步复制、同步复制 (NDB Cluster, Group Replication这两种技术) 、延迟复制等模式。MySQL的复制包括了多种方式,一种是基于Binlog的原生复制方式,这个也是最早的复制方式。MySQL提供了原生的复制,是异步复制。也就是主库的数据落地之后,并不关心备库的日志是否落库,从而可能导致较多的数据丢失。
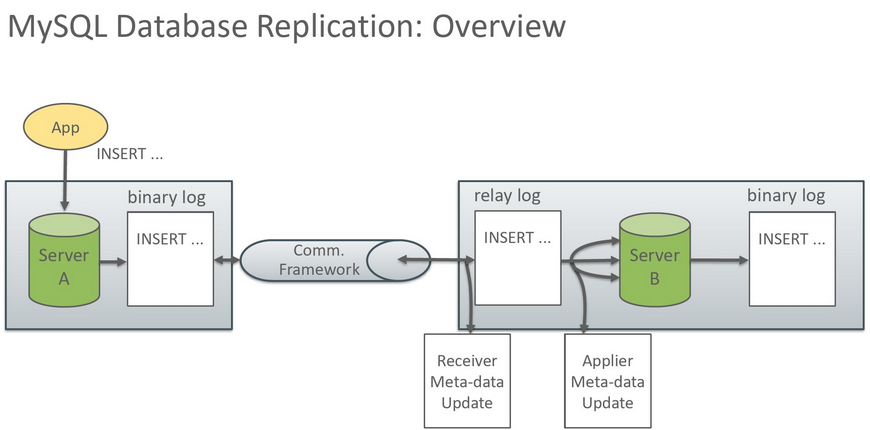
从MySQL5.5 开始引入了一种半同步复制(Semi-Sync)功能,是以plugin的方式提供服务。该功能可以确保主服务器和访问链中至少一台从服务器之间的数据一致性和冗余,从而可以减少数据的丢失。半同步复制大大减少了“Binlog events只存在故障MASTER上”的问题。半同步复制时,通常是一台主库并配置多个备库,在这样的复制拓扑中,只有在至少一台从服务器确认更新已经收到并写入了其中继日志 (Relay Log) 之后,主库才完成提交。如果网络出现故障,导致复制超时,主库会暂时切换到原生的异步复制模式。在这种情况下,此时备库也可能会丢失事务。
GTID (Global Transaction ID)就是全局事务ID,是用来强化数据库在主备复制场景下,可以有效保证主备一致性、提高故障恢复、容错能力。是一个已提交事务的编号,并且是一个全局唯一的编号,在MySQL中,GTID由UUID和TID组成。UUID是一个MySQL实例的唯一标识,TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。GTID在Replication的 Failover方面很方便。
在 GTID 出现之前,在配置主备复制的时候,首先需要确认Event在那个Binlog文件,及其偏移量。假设有 A(MASTER)、B(SLAVE)、C(SLAVE) 三个实例,如果主库宕机后,需要通过CHANGE MASTER TO MASTER_HOST='XXX', MASTER_LOG_FILE='XXX', MASTER_LOG_POS=NNNNN指向新库。这里的难点在于,同一个事务在每台机器上所在的 Binlog文件名和偏移都不同,这也就意味着需要知道新主库的文件以及偏移量,对于有一个主库+多个备库的场景,如果主库宕机,那么需要手动从备库中选出最新的备库,升级为主,然后重新配置备库。这就导致操作特别复杂,不方便实施,这也就是为什么需要MHA、MMM 这样的管理工具。之所以会出现上述的问题,主要是由于各个实例Binlog中的Event以及Event顺序是一致的,但是Binlog+Position是不同的,是通过GTID提供了对于事物的全局一致ID,主备复制时,只需要知道这个ID 即可。MySQL会记录那些事物已经执行,通过 GTID也就知道接下来要执行那些事务。当有了GTID 之后,就显得非常的简单,因为同一事务的GTID 在所有节点上的值一致,那么就可以直接根据GTID就可以完成Failover操作。
在GTID出现以前,对切换一致性要求高的环境,基本都是MHA为主,最简单,现有业务不用改造,可以实现DB故障自动切换。在GTID出现后,就有点落后了,特别是MySQL5.7的增强半同步+GTID,基本不需要MHA。
回顾一下历年来可能用过的复制方式
MMM(MASTER-MASTER replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM使用Perl语言开发,主要用来监控和管理MySQL MASTER-MASTER(双主)复制,虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热,可以说MMM这套脚本程序一方面实现了故障切换的功能,另一方面其内部附加的工具脚本也可以实现多个SLAVE的read负载均衡。由于MMM无法完全的保证数据一致性,所以MMM适用于对数据的一致性要求不是很高。对于那些对数据的一致性要求很高的业务,非常不建议采用MMM这种高可用架构。
Heartbeat+DRBD
本方案采用Heartbeat双机热备软件来保证数据库的高稳定性和连续性,数据的一致性由DRBD(DistributedReplicatedBlockDevice)这个工具来保证。默认情况下只有一台MySQL在工作,当主MySQL服务器出现问题后,系统将自动切换到备机上继续提供服务,当主数据库修复完毕,又将服务切回继续由主MySQL提供服务。
MHA (MASTER High Availability)
MHA(MASTER High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MySQL Cluster
MySQL Cluster是一个基于NDB(Network Database) Cluster存储引擎的完整的分布式数据库系统。不仅仅具有高可用性,而且可以自动切分数据,冗余数据等高级功能。和Oracle Real Cluster Application不太一样的是,MySQL Cluster 是一个Share Nothing的架构,各个MySQL Server之间并不共享任何数据,高度可扩展以及高度可用方面的突出表现是其最大的特色。
MySQL Cluster 实际上是在无共享存储设备的情况下实现的一种完全分布式数据库系统,其主要通过 NDB Cluster存储引擎来实现。MySQL Cluster 刚刚诞生的时候可以说是一个可以对数据进行持久化的内存数据库,所有数据和索引都必须装载在内存中才能够正常运行,但是最新的 MySQL Cluster 版本已经可以做到仅仅将所有索引装载在内存中即可,实际的数据可以不用全部装载到内存中。
MySQL Cluster 的环境主要由以下三部分组成:SQL节点,Data节点,Manage节点
SQL 节点:也就是我们常说的MySQL Server。主要负责实现一个数据库在存储层之上的所有事情,比如连接管理,Query 优化和响应 ,Cache 管理等等,只有存储层的工作交给了NDB 数据节点去处理了。也就是说,在纯粹的MySQL Cluster 环境中的SQL 节点,可以被认为是一个不需要提供任何存储引擎的MySQL服务器,因为他的存储引擎有Cluster 环境中的NDB 节点来担任。所以,SQL 层各MySQL服务器的启动与普通的MySQL Server 启动也有一定的区别,必须要添加ndbcluster参数选项才行。我们可以添加在my.cnf配置文件中,也可以通过启动命令行来指定。
Data节点:Storage层的NDB 数据节点,也就是上面说的NDB Cluster。最初的NDB是一个内存式存储引擎,当然也会将数据持久化到存储设备上。最新的NDB Cluster存储引擎已经改进了这一点,可以选择数据是全部加载到内存中还是仅仅加载索引数据。NDB节点主要是实现底层数据存储功能,来保存Cluster 的数据。每一个Cluster节点保存完整数据的一个Fragment,也就是一个数据分片(或者一份完整的数据,视节点数目和配置而定),所以只要配置得当,MySQL Cluster在存储层不会出现单点的问题。在Manager节点的配置文件config.ini,可以通过NoOfReplicas参数控制数据存放的份数。
Manage节点:管理节点负责整个Cluster集群中各个节点的管理工作,包括集群的配置,启动关闭各节点,对各个节点进行常规维护,以及实施数据的备份恢复等。管理节点会获取整个Cluster环境中各节点的状态和错误信息,并且将各Cluster集群中各个节点的信息反馈给整个集群中其他的所有节点。由于管理节点上保存了整个Cluster环境的配置,同时担任了集群中各节点的基本沟通工作,所以他必须是最先被启动的节点。
PXC(Percona XtraDB Cluster)
PXC实现了服务高可用,数据同步时是并发复制。但是仅支持InnoDB引擎,所有的表都要有主键。锁冲突、死锁问题相对较多等等问题。如果要做集群,还需要借助Galera。就是集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,都是基于Galera的,所以这里都统称为Galera Cluster,因为Galera本身是具有多主特性的,所以Galera Cluster也就是Multi-MASTER的集群架构。假定配置了3个节点的MySQL Cluster,其中每个节点都可以作为主节点,三个节点是对等的,这种一般称为Multi-MASTER架构,当有客户端要写入或者读取数据时,随便连接哪个实例都是一样的,读到的数据是相同的,写入某一个节点之后,集群自己会将新数据同步到其它节点上面,这种架构不共享任何数据,是一种高冗余架构。下面是常用到的参数,其中WSREP是Write Set Replication的缩写。
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so wsrep_provider_options= "gcs.fc_limit =2048;gcs.sync_donor=no;gcache.size=4G" wsrep_cluster_name=pxc-ohsdba wsrep_cluster_address=gcomm://192.168.56.21,192.168.56.22,192.168.56.23 wsrep_node_address=192.168.56.21 wsrep_sst_method=xtrabackup-v2 wsrep_sst_auth=sstuser:oracle wsrep_slave_threads=64 wsrep_sync_wait=1 binlog_format=row default_storage_engine=InnoDB innodb_autoinc_lock_mode=2http://galeracluster.com/documentation-webpages/galeraparameters.html#setting-galera-parameters-in-mysql
http://galeracluster.com/documentation-webpages/mysqlwsrepoptions.html
http://releases.galeracluster.com/mysql-wsrep-5.7/release-notes-mysql-wsrep-5.7.23-25.15.txt
组复制的相关参数
http://datacharmer.blogspot.com/2017/01/mysql-group-replication-installation.html
******************************************************************* [mysqld] user=mysql server_id=_SERVER_ID_ gtid_mode=ON enforce_gtid_consistency=ON master_info_repository=TABLE relay_log_info_repository=TABLE binlog_checksum=NONE log_slave_updates=ON log_bin=mysql-bin relay-log=relay binlog_format=ROW log-error=mysqld.err plugin-load = group_replication.so group_replication = FORCE_PLUS_PERMANENT transaction-write-set-extraction = XXHASH64 # MURMUR32, NONE group_replication_start_on_boot = OFF group_replication_bootstrap_group = OFF group_replication_group_name = 550fa9ee-a1f8-4b6d-9bfe-c03c12cd1c72 group_replication_local_address = '127.0.0.1:3307' group_replication_group_seeds = '127.0.0.1:3307,127.0.0.1:3308,127.0.0.1:3309' ******************************************************************* ransaction_write_set_extraction=XXHASH64 loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" loose-group_replication_start_on_boot=off loose-group_replication_local_address= "127.0.0.1:24901" loose-group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903" loose-group_replication_bootstrap_group=off ********************************************************************
The loose- prefix used for the group_replication variables above instructs the server to continue to start if the Group Replication plugin has not been loaded at the time the server is started.有时候,你可能会看到loose-group_replication和group_replication开头的参数。其实都是一样的。区别是如果加上loose-这个前缀表示,如果复制的plugin没有loaded的情况下也运行启动。可以参考下面的链接https://docs.oracle.com/cd/E17952_01/mysql-5.7-en/group-replication-configuring-instances.html
DBdeployer
DBdeployer is a tool that deploys MySQL database servers easily. This is a port of MySQL-Sandbox, originally written in Perl, and re-designed from the ground up in Go. See the features comparison for more detail.
这是一个非常不错的工具,通过MySQL Sandbox帮我们快速的建立实验环境。下面是多主复制的脚步样本。
Group replication脚本mm_gr.sh
# ----------------------------------------------------------------------------
#!/bin/bash
# mm_gr.sh : installs MySQL Group Replication
MYSQL_VERSION=$1
[ -z "$MYSQL_VERSION" ] && MYSQL_VERSION=5.7.17
make_multiple_sandbox --gtid --group_directory=GR $MYSQL_VERSION
if [ "$?" != "0" ] ; then exit 1 ; fi
multi_sb=$HOME/sandboxes/GR
baseport=$($multi_sb/n1 -BN -e 'select @@port')
baseport=$(($baseport+99))
port1=$(($baseport+1))
port2=$(($baseport+2))
port3=$(($baseport+3))
for N in 1 2 3
do
myport=$(($baseport+N))
options=(
binlog_checksum=NONE
log_slave_updates=ON
plugin-load=group_replication.so
group_replication=FORCE_PLUS_PERMANENT
group_replication_start_on_boot=OFF
group_replication_bootstrap_group=OFF
transaction_write_set_extraction=XXHASH64
report-host=127.0.0.1
loose-group_replication_group_name="aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
loose-group_replication_local_address="127.0.0.1:$myport"
loose-group_replication_group_seeds="127.0.0.1:$port1,127.0.0.1:$port2,127.0.0.1:$port3"
loose-group-replication-single-primary-mode=off
)
$multi_sb/node$N/add_option ${options[*]}
user_cmd='reset master;'
user_cmd="$user_cmd CHANGE MASTER TO MASTER_USER='rsandbox', MASTER_PASSWORD='rsandbox' FOR CHANNEL 'group_replication_recovery';"
$multi_sb/node$N/use -v -u root -e "$user_cmd"
done
START_CMD="SET GLOBAL group_replication_bootstrap_group=ON;"
START_CMD="$START_CMD START GROUP_REPLICATION;"
START_CMD="$START_CMD SET GLOBAL group_replication_bootstrap_group=OFF;"
$multi_sb/n1 -v -e "$START_CMD"
sleep 1
$multi_sb/n2 -v -e 'START GROUP_REPLICATION;'
sleep 1
$multi_sb/n3 -v -e 'START GROUP_REPLICATION;'
sleep 1
$multi_sb/use_all 'select * from performance_schema.replication_group_members'
Reference
https://github.com/datacharmer/dbdeployer
https://github.com/yoshinorim/mha4MySQL-manager/wiki
http://mysql-mmm.orghttp://linux-ha.org/wiki/Main_Page
http://www.drbd.org/
http://galeracluster.com/downloads/
http://releases.galeracluster.com/mysql-wsrep-5.7/source/mysql-wsrep-5.7.23-25.15.tar.gz
https://www.percona.com/doc/percona-xtradb-cluster/LATEST/overview.html
http://datacharmer.blogspot.com/2017/01/mysql-group-replication-vs-multi-source.html
http://datacharmer.blogspot.com/2017/01/mysql-group-replication-installation.html
https://github.com/datacharmer/mysql-replication-samples
